
A detailed look at how Large Language Models are transforming the entire video supply chain, from content creation, distribution and security, to personalisation, recommendations, advertising and analytics.

It isn't easy to think of a technology in recent years that has transformed so many aspects of our day-to-day life as fast as Large Language Models and generative AI. Indeed, many commentators have had to reach back to previous centuries to come up with something that has had a similar impact. The printing press, electricity, the telegraph, the automobile, penicillin, and the silicon chip have all been mentioned in a similar context. And given the impact those had on the world, you can see the amount of change we are currently living through.
It is easy to forget that OpenAI’s ChapGPT, which started the current development cycle, was only introduced publicly to the world in November 2022.
So, where are we with the technology? How exactly are LLMs and generative AI transforming the TV industry? Judging by the number of people who attended a packed IBC2023 presentation I did on the topic, these are questions that many people want answers to. We’ll attempt to address them below.
AI is already well established
First, it is good to remember that AI has been transforming the TV industry for several years. We first wrote about how it impacts in depth at the start of 2019, and since then, its use has become extensive.
At VO, AI is vital to our technology stack and customer offerings. We use it for audience segmentation in Targeted TV Advertising and for optimizing content catalogs and recommendations. We use it to predict QoS incidents, measure QoE, optimize video playback, and anticipate TV platform capacity. We use it to help our anti-piracy experts track and detect illegal use of services on the web and detect fraudulent behaviors.
In the industry as a whole, it is being used across the entire chain from content development through production and onto distribution.
The introduction of LLMs, however, represents an inflection point that can provide us with far more capable AI than we have used before and will likely revolutionize — and I do not use the word lightly — the way that many aspects of the TV industry work.
LLMs: An AI with multiple abilities
To give a brief overview, Large Language Models are a type of AI that can understand and generate natural language. They are built on a deep learning model that analyses a vast amount of text — millions if not billions of words — to predict what word will come next effectively. They are then trained by human input to refine that process further, ‘learning’ as they go on, before being released for use (the ‘P’ in ChatGPT stands for ‘pre-trained’). Further interaction with users leads to more training, and they have exhibited unexpected capabilities for in-context learning, instruction following, and step-by-step reasoning. They have also gained multi-modal ability and proven adept at manipulating and generating images, video, and audio.
The explosion in their popularity has been matched with an explosion in understanding what they are capable of. They take AI far beyond its initial deployments in industry workflows as primarily a way of automating tasks such as analyzing large data sets. I showed a slide at the IBC2023 presentation that illustrates some of the use cases created when you use LLMs to boost the scope of TV data analytics.
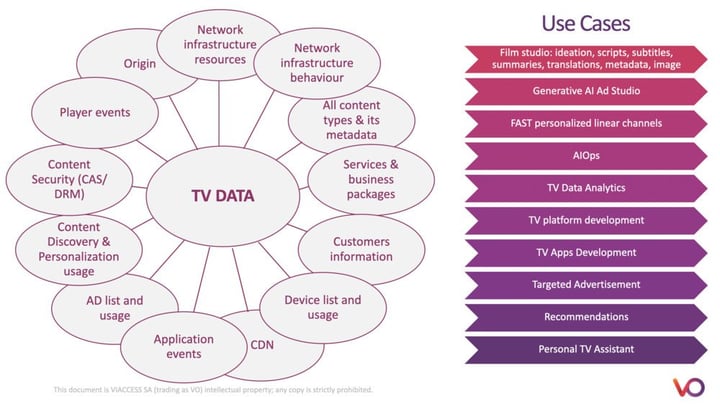
Overall, the priority for companies is to start using LLMs to enhance their productivity. This encompasses processes, workflows, software development, and document management) after this comes innovation and the task of building new features for their customers.
The options they have are expanding all the time as many companies are involved in rapidly developing LLMs for widespread use. OpenAI’s ChatGPT competes with Bard by Google, stability.ai, Midjourney, GitHub Copilot, Llama by Meta, and many more. Interestingly, the market supports both open-source and commercial LLMs, and the availability of open-source LLMs for commercial use is liable to help drive the next stage of industry deployment. Open-source LLMs can be operated in a secure environment without leaking data.
Companies can reuse LLMs through prompt engineering and instructions, meaning they may need to build new competencies in prompt engineering. And/or they can refine LLMs with additional training on specific datasets and instructions, fine-tuning them for specific tasks. Either way, important skill sets need to be developed to maximize their potential, and LLMOps are set to become a vital part of the IT landscape over the next few years.
The good news is that costs are coming down all the time. Six months ago, Meta’s Llama2 LLM was revealed to have cost several million dollars to train in terms of cloud computing alone. In September, researchers creating the FLM-101B model said they bought it in on a budget of $100,000. Sure, we are not necessarily comparing like for like here, but the direction of travel is noticeable.
Data also suggests that fine-tuned “small” LLMs designed for specific tasks, such as content recommendation, can outperform large models. With a new generation of neural processors (NPUs), it is even possible to host LLMs on user devices, whether a future-connected TV or a smartphone.
The need for responsible AI
Progress is beyond rapid, and there are changes almost weekly. There remain challenges to LLM deployment in their current configurations, however, that businesses need to consider carefully.
First, there are operational challenges. The quality of output needs to be considered carefully, with guardrails in place to safeguard against toxicity and attention paid to nondeterministic results, hallucinations, and catastrophic forgetting, which is where a neural network can forget previously learned information as new information is added.
Reinforcement learning from human feedback is needed to maintain LLMs’ effectiveness, while, as a whole, the industry needs to prioritize ongoing necessary innovations in benchmarking, as current benchmarks do not cover all aspects of LLM operations.
Sustainability also needs to be taken into consideration. Meta’s Llama2 LLM was trained over 3,311,616 GPU hours, which consumed 539 tCO2eq — roughly the same as the yearly carbon output of 60 European households.
Then there are the legal challenges, which we’ve summarised below.
Data protection and privacy, such as how the data used to train and feed the models is collected, processed, and stored, and whether it complies with the GDPR or the CCPA.
Intellectual property and ownership, who owns the rights to the content or data generated by the models, and whether it infringes on the rights of others, such as authors or artists.
Liability and accountability, such as who is responsible for the actions and outcomes of the models, whether they are accurate, reliable, and fair, and whether they cause any harm or damage to others.
Ethics and governance, such as how the models are designed, developed, and deployed, and whether they adhere to the ethical principles and standards of the relevant domains and professions.
Some of these challenges are significant. But we have some tools to cope with them already. There are LLMs that have only been trained on rights-cleared content, such as Adobe’s Firefox, that the company is integrating into Photoshop and Premiere Pro; and Microsoft has done an excellent job of integrating OpenAI into the existing robust privacy framework of its Azure cloud services. Existing technologies that we are already experts on at VO, such as DRM, fingerprinting, and watermarking, can help further with data protection and privacy too.
New tools are being developed all the time as well. There is a lot of current interest in Fully Homomorphic Cryptography, which can do mathematical computations on encrypted content without decrypting it. This effectively allows users to have a fully confidential chat with a Large Language Model trained using this method to the extent that the LLM is not aware of what the discussion has been about.
Next steps in the LLM revolution
‘Revolution’ is a term that often gets overused by industry and marketing, but there is no other word to describe the impact of LLMs. In under a year, they have become almost ubiquitous and tend to change everything they touch.
We are seeing a massive increase in LLMOps as a result, with the TV industry at the forefront of developing new competencies to handle the rapidly evolving capabilities of LLMs. And we are increasingly seeing how existing and developing security technologies can be applied to their use to improve their operation in a post-GDPR environment.
By the time of IBC2024, much will have changed. But one crucial thing to consider is how we allow these changes to unfold across the industry. I like to use the phrase augmented intelligence rather than artificial intelligence, which nicely encapsulates the concept that we are developing these tools to empower human beings, not replace them. Augmented Intelligence features the same disciplines and tools as Artificial Intelligence, but it uses them to a different end and always remembers that humans are a vital part of any system.
